Introduction
LabCAS is a platform for building a data commons.
It provides the following:
- A secure, reliable means to capture, process, manage, search, and enable analysis of scientific data
- Plug in of analytical methods
- Repeatable data processing pipelines
- Integrate visualization and other analytical tools
- Support data delivery to and from sites
LabCAS uses data models and data elements (metadata) to capture data consistently across the NIST Data Commons. Data can be captured and added over time, and it is linked and available for integration with different analytical methods and tools to drive data-driven discovery. This results in a consistent data architecture.
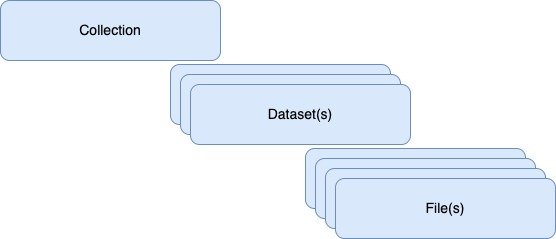
Data in LabCAS is organized in a hierarchical structure with collections at the top level, datasets below collections, and files below datasets. Collections are used to group data logically, such as by consortium. Datasets are used to further subcategorize data within a collection, such as a submission for an interlaboratory study. Files are the smallest unit of data and can be stored at the collection level or within a dataset.